Дисперсия в статистике находится как индивидуальных значений признака в квадрате от . В зависимости от исходных данных она определяется по формулам простой и взвешенной дисперсий:
1. (для несгруппированных данных) вычисляется по формуле:
2. Взвешенная дисперсия (для вариационного ряда):
 где n — частота (повторяемость фактора Х)
где n — частота (повторяемость фактора Х)
Пример нахождения дисперсии
На данной странице описан стандартный пример нахождения дисперсии, также Вы можете посмотреть другие задачи на её нахождение
Пример 1. Имеются следующие данные по группе из 20 студентов заочного отделения. Нужно построить интервальный ряд распределения признака, рассчитать среднее значение признака и изучить его дисперсию
 Построим интервальную группировку. Определим размах интервала по формуле:
Построим интервальную группировку. Определим размах интервала по формуле:
![]() где X max– максимальное значение группировочного признака;
где X max– максимальное значение группировочного признака;
X min–минимальное значение группировочного признака;
n – количество интервалов:
Принимаем n=5. Шаг равен: h = (192 — 159)/ 5 = 6,6
Составим интервальную группировку
 Для дальнейших расчетов построим вспомогательную таблицу:
Для дальнейших расчетов построим вспомогательную таблицу:
 X’i– середина интервала. (например середина интервала 159 – 165,6 = 162,3)
X’i– середина интервала. (например середина интервала 159 – 165,6 = 162,3)
Среднюю величину роста студентов определим по формуле средней арифметической взвешенной:
 Определим дисперсию по формуле:
Определим дисперсию по формуле:
Формулу дисперсии можно преобразовать так:
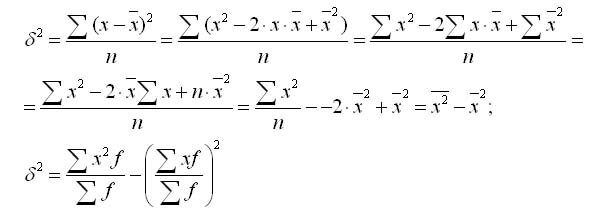
Из этой формулы следует, что дисперсия равна разности средней из квадратов вариантов и квадрата и средней.
Дисперсия в вариационных рядах с равными интервалами по способу моментов может быть рассчитана следующим способом при использовании второго свойства дисперсии (разделив все варианты на величину интервала). Определении дисперсии , вычисленной по способу моментов, по следующей формуле менее трудоемок:

где i - величина интервала;
А - условный ноль, в качестве которого удобно использовать середину интервала, обладающего наибольшей частотой;
m1 — квадрат момента первого порядка;
m2 — момент второго порядка
(если в статистической совокупности признак изменяется так, что имеются только два взаимно исключающих друг друга варианта, то такая изменчивость называется альтернативной) может быть вычислена по формуле:

Подставляя в данную формулу дисперсии q =1- р, получаем:

Виды дисперсии
Общая дисперсия измеряет вариацию признака по всей совокупности в целом под влиянием всех факторов, обуславливающих эту вариацию. Она равняется среднему квадрату отклонений отдельных значений признака х от общего среднего значения х и может быть определена как простая дисперсия или взвешенная дисперсия.
характеризует случайную вариацию, т.е. часть вариации, которая обусловлена влиянием неучтенных факторов и не зависящую от признака-фактора, положенного в основание группировки. Такая дисперсия равна среднему квадрату отклонений отдельных значений признака внутри группы X от средней арифметической группы и может быть вычислена как простая дисперсия или как взвешенная дисперсия.
Таким образом, внутригрупповая дисперсия измеряет вариацию признака внутри группы и определяется по формуле:

где хi - групповая средняя;
ni - число единиц в группе.
Например, внутригрупповые дисперсии, которые надо определить в задаче изучения влияния квалификации рабочих на уровень производительности труда в цехе показывают вариации выработки в каждой группе, вызванные всеми возможными факторами (техническое состояние оборудования, обеспеченность инструментами и материалами, возраст рабочих, интенсивность труда и т.д.), кроме отличий в квалификационном разряде (внутри группы все рабочие имеют одну и ту же квалификацию).
Средняя из внутри групповых дисперсий отражает случайную , т. е. ту часть вариации, которая происходила под влиянием всех прочих факторов, за исключением фактора группировки. Она рассчитывается по формуле:

Характеризует систематическую вариацию результативного признака, которая обусловлена влиянием признака-фактора, положенного в основание группировки. Она равняется среднему квадрату отклонений групповых средних от общей средней. Межгрупповая дисперсия рассчитывается по формуле:

Правило сложения дисперсии в статистике
Согласно правилу сложения дисперсий общая дисперсия равна сумме средней из внутригрупповых и межгрупповых дисперсий:
![]()
Смысл этого правила заключается в том, что общая дисперсия, которая возникает под влиянием всех факторов, равняется сумме дисперсий, которые возникают под влиянием всех прочих факторов, и дисперсии, возникающей за счет фактора группировки.
Пользуясь формулой сложения дисперсий, можно определить по двум известным дисперсиям третью неизвестную, а также судить о силе влияния группировочного признака.
Свойства дисперсии
1. Если все значения признака уменьшить (увеличить) на одну и ту же постоянную величину, то дисперсия от этого не изменится.
2. Если все значения признака уменьшить (увеличить) в одно и то же число раз n, то дисперсия соответственно уменьшится (увеличить) в n^2 раз.
Дисперсия случайной величины - мера разброса данной случайной величины , то есть её отклонения от математического ожидания. В статистике для обозначения дисперсии часто употребляется обозначение (сигма в квадрате). Квадратный корень из дисперсии , равный , называется стандартным отклонением или стандартным разбросом. Стандартное отклонение измеряется в тех же единицах, что и сама случайная величина, а дисперсия измеряется в квадратах этой единицы измерения.
Хотя для оценки всей выборки очень удобно использовать лишь одно значение (такое как среднее значение или моду и медиану), этот подход легко может привести к неправильным выводам. Причина такого положения лежит не в самой величине, а в том, что одна величина никак не отражает разброс значений данных.
Например, в выборке:
среднее значение равно 5.
Однако, в самой выборке нет ни одного элемента со значением 5. Возможно, Вам потребуется знать степень близости каждого элемента выборки к ее среднему значению. Или, другими словами, вам потребуется знать дисперсию значений. Зная степень изменения данных, Вы можете лучше интерпретировать среднее значение , медиану и моду . Степень изменения значений выборки определяется путем вычисления их дисперсии и стандартного отклонения.
Дисперсия и квадратный корень из дисперсии, называемый стандартным отклонением, характеризуют среднее отклонение от среднего значения выборки. Среди этих двух величин наибольшее значение имеет стандартное отклонение . Это значение можно представить как среднее расстояние, на котором находятся элементы от среднего элемента выборки.
Дисперсию трудно интерпретировать содержательно. Однако, квадратный корень из этого значения является стандартным отклонением и хорошо поддается интерпретации.
Стандартное отклонение вычисляется путем определения сначала дисперсии и затем вычисления квадратного корня из дисперсии.
Например, для массива данных, приведенных на рисунке, будут получены следующие значения:

Рисунок 1
Здесь среднее значение квадратов разностей равно 717,43. Для получения стандартного отклонения осталось лишь взять квадратный корень из этого числа.
Результат составит приблизительно 26,78.
Следует помнить, что стандартное отклонение интерпретируется как среднее расстояние, на котором находятся элементы от среднего значения выборки.
Стандартное отклонение показывает, насколько хорошо среднее значение описывает всю выборку.
Допустим, Вы являетесь руководителем производственного отдела по сборке ПК. В квартальном отчете говорится, что выпуск за последний квартал составил 2500 ПК. Плохо это или хорошо? Вы попросили (или уже в отчете есть эта графа) в отчете отобразить стандартное отклонение по этим данным. Цифра стандартного отклонения, например, равна 2000. Становится понятным для Вас, как руководителя отдела, что производственная линия требует лучшего управления (слишком большие отклонения по количеству собираемых ПК).
Вспомним: при большой величине стандартного отклонения данные широко разбросаны относительно среднего значения, а при маленькой – они группируются близко к среднему значению.
Четыре статистические функции ДИСП(), ДИСПР(), СТАНДОТКЛОН() и СТАНДОТКЛОНП() – предназначены для вычисления дисперсии и стандартного отклонения чисел в интервале ячеек. Перед тем как вычислять дисперсию и стандартное отклонение набора данных, нужно определить, представляют ли эти данные генеральную совокупность или выборку из генеральной совокупности. В случае выборки из генеральной совокупности следует использовать функции ДИСП() и СТАНДОТКЛОН(), а в случае генеральной совокупности – функции ДИСПР() и СТАНДОТЛОНП():
| Генеральная совокупность | Функция |
 | ДИСПР() |
 | СТАНДОТЛОНП() |
| Выборка | |
 | ДИСП() |
 | СТАНДОТКЛОН() |
Дисперсия (а так же стандартное отклонение), как мы отмечали, свидетельствуют о том, в какой степени входящие в набор данных величины разбросаны вокруг среднего арифметического.
Малое значение дисперсии или стандартного отклонения говорит о том, что все данные сосредоточены вокруг среднего арифметического, а большое значение этих величин – о том, что данные разбросаны в широком диапазоне значений.
Дисперсию достаточно трудно интерпретировать содержательно (что значит малое значение, большое значение?). Выполнение Задания 3 позволит визуально, на графике, показать смысл дисперсии для набора данных.
Задания
· Задание 1.
· 2.1. Дать понятия: дисперсия и стандартное отклонение; их символьное обозначение при статистической обработке данных.
· 2.2. Оформить рабочий лист в соответствии с рисунком 1 и произвести необходимые расчеты.
· 2.3. Привести основные формулы, используемые при расчетах
· 2.4. Пояснить все обозначения ( , , )
· 2.5. Пояснить практическое значение понятия дисперсия и стандартное отклонение.
Задание 2.
1.1. Дать понятия: генеральная совокупность и выборка; математическое ожидание и среднее арифметическое их символьное обозначение при статистической обработке данных.
1.2. В соответствии с рисунком 2 оформить рабочий лист и произвести расчеты.
1.3. Привести основные формулы, используемые при расчетах (для генеральной совокупности и выборке).

Рисунок 2
1.4. Объяснить, почему возможны получения таких значений средних арифметических в выборках как 46,43 и 48,78 (см. файл Приложение). Сделать выводы.
Задание 3.
Имеется две выборки с различным набором данных, но среднее для них будет одинаковым:

Рисунок 3
3.1. Оформить рабочий лист в соответствии с рисунком 3 и произвести необходимые расчеты.
3.2. Приведите основные формулы расчета.
3.3. Постройте графики в соответствии с рисунками 4, 5.
3.4. Поясните полученные зависимости.
3.5. Аналогичные вычисления проведите для данных двух выборок.
Исходная выборка 11119999
Значения второй выборки подбираете так, что бы среднее арифметическое для второй выборки было таким же, например,:

Подберите значения для второй выборки самостоятельно. Оформите вычисления и построения графиков подобно рисункам 3, 4, 5. Покажите основные формулы, которые использовали при вычислениях.
Сделайте соответствующие выводы.
Все задания оформить в виде отчета со всеми необходимыми рисунками, графиками, формулами и краткими пояснениями.
Примечание: построение графиков обязательно пояснить с рисунками и краткими пояснениями.
Часто в статистике при анализе какого-либо явления или процесса необходимо учитывать не только информацию о средних уровнях исследуемых показателей, но и разброс или вариацию значений отдельных единиц , которая является важной характеристикой изучаемой совокупности.
В наибольшей степени вариации подвержены курсы акций, объемы спроса и предложения, процентные ставки в разные периоды времени и в разных местах.
Основными показателями, характеризующими вариацию , являются размах, дисперсия, среднее квадратическое отклонение и коэффициент вариации.
Размах вариации представляет собой разность максимального и минимального значений признака: R = Xmax – Xmin . Недостатком данного показателя является то, что он оценивает только границы варьирования признака и не отражает его колеблемость внутри этих границ.
Дисперсия лишена этого недостатка. Она рассчитывается как средний квадрат отклонений значений признака от их средней величины:
Упрощенный способ расчета дисперсии осуществляется с помощью следующих формул (простой и взвешенной):
Примеры применения данных формул представлены в задачах 1 и 2.
Широко распространенным на практике показателем является среднее квадратическое отклонение :
Среднее квадратическое отклонение определяется как квадратный корень из дисперсии и имеет ту же размеренность, что и изучаемый признак.
Рассмотренные показатели позволяют получить абсолютное значение вариации, т.е. оценивают ее в единицах измерения исследуемого признака. В отличие от них, коэффициент вариации измеряет колеблемость в относительном выражении - относительно среднего уровня, что во многих случаях является предпочтительнее.
Формула для расчета коэффициента вариации.
Примеры решения задач по теме «Показатели вариации в статистике»
Задача 1 . При изучении влияния рекламы на размер среднемесячного вклада в банках района обследовано 2 банка. Получены следующие результаты:
Определить:
1) для каждого банка: а) средний размер вклада за месяц; б) дисперсию вклада;
2) средний размер вклада за месяц для двух банков вместе;
3) Дисперсию вклада для 2-х банков, зависящую от рекламы;
4) Дисперсию вклада для 2-х банков, зависящую от всех факторов, кроме рекламы;
5) Общую дисперсию используя правило сложения;
6) Коэффициент детерминации;
7) Корреляционное отношение.
Решение
1) Составим расчетную таблицу для банка с рекламой . Для определения среднего размера вклада за месяц найдем середины интервалов. При этом величина открытого интервала (первого) условно приравнивается к величине интервала, примыкающего к нему (второго).
Средний размер вклада найдем по формуле средней арифметической взвешенной:
29 000/50 = 580 руб.
Дисперсию вклада найдем по формуле:
23 400/50 = 468
Аналогичные действия произведем для банка без рекламы :
2) Найдем средний размер вклада для двух банков вместе. Хср =(580×50+542,8×50)/100 = 561,4 руб.
3) Дисперсию вклада, для двух банков, зависящую от рекламы найдем по формуле: σ 2 =pq (формула дисперсии альтернативного признака). Здесь р=0,5 – доля факторов, зависящих от рекламы; q=1-0,5, тогда σ 2 =0,5*0,5=0,25.
4) Поскольку доля остальных факторов равна 0,5, то дисперсия вклада для двух банков, зависящая от всех факторов кроме рекламы тоже 0,25.
5) Определим общую дисперсию, используя правило сложения.
= (468*50+636,16*50)/100=552,08
= [(580-561,4)250+(542,8-561,4)250] / 100= 34 596/ 100=345,96
σ 2 = σ 2 факт + σ 2 ост = 552,08+345,96 = 898,04
6) Коэффициент детерминации η 2 = σ 2 факт / σ 2 = 345,96/898,04 = 0,39 = 39% - размер вклада на 39% зависит от рекламы.
7) Эмпирическое корреляционное отношение η = √η 2 = √0,39 = 0,62 – связь достаточно тесная.
Задача 2 . Имеется группировка предприятий по величине товарной продукции:
Определить: 1) дисперсию величины товарной продукции; 2) среднее квадратическое отклонение; 3) коэффициент вариации.
Решение
1) По условию представлен интервальный ряд распределения. Его необходимо выразить дискретно, то есть найти середину интервала (х"). В группах закрытых интервалов середину найдем по простой средней арифметической. В группах с верхней границей - как разность между этой верхней границей и половиной размера следующего за ним интервала (200-(400-200):2=100).
В группах с нижней границей – суммой этой нижней границы и половины размера предыдущего интервала (800+(800-600):2=900).
Расчет средней величины товарной продукции делаем по формуле:
Хср = k×((Σ((х"-a):k)×f):Σf)+a. Здесь а=500 - размер варианта при наибольшей частоте, k=600-400=200 - размер интервала при наибольшей частоте. Результат поместим в таблицу:
Итак, средняя величина товарной продукции за изучаемый период в целом равна Хср = (-5:37)×200+500=472,97 тыс. руб.
2) Дисперсию найдем по следующей формуле:
σ 2 = (33/37)*2002-(472,97-500)2 = 35 675,67-730,62 = 34 945,05
3) среднее квадратическое отклонение: σ = ±√σ 2 = ±√34 945,05 ≈ ±186,94 тыс. руб.
4) коэффициент вариации: V = (σ /Хср)*100 = (186,94 / 472,97)*100 = 39,52%
 .
.
Обратно,
если -
неотрицательная п.в. функция, такая
что  ,
то существует абсолютно непрерывная
вероятностная мера на такая,
что является
её плотностью.
,
то существует абсолютно непрерывная
вероятностная мера на такая,
что является
её плотностью.
Замена меры в интеграле Лебега:
 ,
,
где любая борелевская функция, интегрируемая относительно вероятностной меры .
Дисперсия, виды и свойства дисперсии Понятие дисперсии
Дисперсия в статистике находится как среднее квадратическое отклонение индивидуальных значений признака в квадрате от средней арифметической. В зависимости от исходных данных она определяется по формулам простой и взвешенной дисперсий:
1. Простая дисперсия (для несгруппированных данных) вычисляется по формуле:
![]()
2. Взвешенная дисперсия (для вариационного ряда):

где n - частота (повторяемость фактора Х)
Пример нахождения дисперсии
На данной странице описан стандартный пример нахождения дисперсии, также Вы можете посмотреть другие задачи на её нахождение
Пример 1. Определение групповой, средней из групповой, межгрупповой и общей дисперсии
Пример 2. Нахождение дисперсии и коэффициента вариации в группировочной таблице
Пример 3. Нахождение дисперсии в дискретном ряду
Пример 4. Имеются следующие данные по группе из 20 студентов заочного отделения. Нужно построить интервальный ряд распределения признака, рассчитать среднее значение признака и изучить его дисперсию

Построим интервальную группировку. Определим размах интервала по формуле:
![]()
где X max– максимальное значение группировочного признака; X min–минимальное значение группировочного признака; n – количество интервалов:
Принимаем n=5. Шаг равен: h = (192 - 159)/ 5 = 6,6
Составим интервальную группировку

Для дальнейших расчетов построим вспомогательную таблицу:

X"i– середина интервала. (например середина интервала 159 – 165,6 = 162,3)
Среднюю величину роста студентов определим по формуле средней арифметической взвешенной:

Определим дисперсию по формуле:
Формулу можно преобразовать так:

Из этой формулы следует, что дисперсия равна разности средней из квадратов вариантов и квадрата и средней.
Дисперсия в вариационных рядах с равными интервалами по способу моментов может быть рассчитана следующим способом при использовании второго свойства дисперсии (разделив все варианты на величину интервала). Определении дисперсии , вычисленной по способу моментов, по следующей формуле менее трудоемок:

где i - величина интервала; А - условный ноль, в качестве которого удобно использовать середину интервала, обладающего наибольшей частотой; m1 - квадрат момента первого порядка; m2 - момент второго порядка
Дисперсия альтернативного признака (если в статистической совокупности признак изменяется так, что имеются только два взаимно исключающих друг друга варианта, то такая изменчивость называется альтернативной) может быть вычислена по формуле:

Подставляя в данную формулу дисперсии q =1- р, получаем:

Виды дисперсии
Общая дисперсия измеряет вариацию признака по всей совокупности в целом под влиянием всех факторов, обуславливающих эту вариацию. Она равняется среднему квадрату отклонений отдельных значений признака х от общего среднего значения х и может быть определена как простая дисперсия или взвешенная дисперсия.
Внутригрупповая дисперсия характеризует случайную вариацию, т.е. часть вариации, которая обусловлена влиянием неучтенных факторов и не зависящую от признака-фактора, положенного в основание группировки. Такая дисперсия равна среднему квадрату отклонений отдельных значений признака внутри группы X от средней арифметической группы и может быть вычислена как простая дисперсия или как взвешенная дисперсия.
Таким образом, внутригрупповая дисперсия измеряет вариацию признака внутри группы и определяется по формуле:

где хi - групповая средняя; ni - число единиц в группе.
Например, внутригрупповые дисперсии, которые надо определить в задаче изучения влияния квалификации рабочих на уровень производительности труда в цехе показывают вариации выработки в каждой группе, вызванные всеми возможными факторами (техническое состояние оборудования, обеспеченность инструментами и материалами, возраст рабочих, интенсивность труда и т.д.), кроме отличий в квалификационном разряде (внутри группы все рабочие имеют одну и ту же квалификацию).
Средняя из внутри групповых дисперсий отражает случайную вариацию, т. е. ту часть вариации, которая происходила под влиянием всех прочих факторов, за исключением фактора группировки. Она рассчитывается по формуле:

Межгрупповая дисперсия характеризует систематическую вариацию результативного признака, которая обусловлена влиянием признака-фактора, положенного в основание группировки. Она равняется среднему квадрату отклонений групповых средних от общей средней. Межгрупповая дисперсия рассчитывается по формуле:

Вычислим в MS EXCEL дисперсию и стандартное отклонение выборки. Также вычислим дисперсию случайной величины, если известно ее распределение.
Сначала рассмотрим дисперсию , затем стандартное отклонение .
Дисперсия выборки
Дисперсия выборки (выборочная дисперсия, sample variance ) характеризует разброс значений в массиве относительно .
Все 3 формулы математически эквивалентны.
Из первой формулы видно, что дисперсия выборки это сумма квадратов отклонений каждого значения в массиве от среднего , деленная на размер выборки минус 1.
дисперсии выборки используется функция ДИСП() , англ. название VAR, т.е. VARiance. С версии MS EXCEL 2010 рекомендуется использовать ее аналог ДИСП.В() , англ. название VARS, т.е. Sample VARiance. Кроме того, начиная с версии MS EXCEL 2010 присутствует функция ДИСП.Г(), англ. название VARP, т.е. Population VARiance, которая вычисляет дисперсию для генеральной совокупности . Все отличие сводится к знаменателю: вместо n-1 как у ДИСП.В() , у ДИСП.Г() в знаменателе просто n. До MS EXCEL 2010 для вычисления дисперсии генеральной совокупности использовалась функция ДИСПР() .
Дисперсию выборки
=КВАДРОТКЛ(Выборка)/(СЧЁТ(Выборка)-1)
=(СУММКВ(Выборка)-СЧЁТ(Выборка)*СРЗНАЧ(Выборка)^2)/ (СЧЁТ(Выборка)-1)
– обычная формула
=СУММ((Выборка -СРЗНАЧ(Выборка))^2)/ (СЧЁТ(Выборка)-1
) –
Дисперсия выборки равна 0, только в том случае, если все значения равны между собой и, соответственно, равны среднему значению . Обычно, чем больше величина дисперсии , тем больше разброс значений в массиве.
Дисперсия выборки является точечной оценкой дисперсии распределения случайной величины, из которой была сделана выборка . О построении доверительных интервалов при оценке дисперсии можно прочитать в статье .
Дисперсия случайной величины
Чтобы вычислить дисперсию случайной величины, необходимо знать ее .
Для дисперсии случайной величины Х часто используют обозначение Var(Х). Дисперсия равна квадрата отклонения от среднего E(X): Var(Х)=E[(X-E(X)) 2 ]
дисперсия вычисляется по формуле:

где x i – значение, которое может принимать случайная величина, а μ – среднее значение (), р(x) – вероятность, что случайная величина примет значение х.
Если случайная величина имеет , то дисперсия вычисляется по формуле:

Размерность дисперсии соответствует квадрату единицы измерения исходных значений. Например, если значения в выборке представляют собой измерения веса детали (в кг), то размерность дисперсии будет кг 2 . Это бывает сложно интерпретировать, поэтому для характеристики разброса значений чаще используют величину равную квадратному корню из дисперсии – стандартное отклонение .
Некоторые свойства дисперсии :
Var(Х+a)=Var(Х), где Х - случайная величина, а - константа.
Var(aХ)=a 2 Var(X)
Var(Х)=E[(X-E(X)) 2 ]=E=E(X 2)-E(2*X*E(X))+(E(X)) 2 =E(X 2)-2*E(X)*E(X)+(E(X)) 2 =E(X 2)-(E(X)) 2
Это свойство дисперсии используется в статье про линейную регрессию .
Var(Х+Y)=Var(Х) + Var(Y) + 2*Cov(Х;Y), где Х и Y - случайные величины, Cov(Х;Y) - ковариация этих случайных величин.
Если случайные величины независимы (independent), то их ковариация равна 0, и, следовательно, Var(Х+Y)=Var(Х)+Var(Y). Это свойство дисперсии используется при выводе .
Покажем, что для независимых величин Var(Х-Y)=Var(Х+Y). Действительно, Var(Х-Y)= Var(Х-Y)= Var(Х+(-Y))= Var(Х)+Var(-Y)= Var(Х)+Var(-Y)= Var(Х)+(-1) 2 Var(Y)= Var(Х)+Var(Y)= Var(Х+Y). Это свойство дисперсии используется для построения .
Стандартное отклонение выборки
Стандартное отклонение выборки - это мера того, насколько широко разбросаны значения в выборке относительно их .
По определению, стандартное отклонение равно квадратному корню из дисперсии :

Стандартное отклонение не учитывает величину значений в выборке , а только степень рассеивания значений вокруг их среднего . Чтобы проиллюстрировать это приведем пример.
Вычислим стандартное отклонение для 2-х выборок: (1; 5; 9) и (1001; 1005; 1009). В обоих случаях, s=4. Очевидно, что отношение величины стандартного отклонения к значениям массива у выборок существенно отличается. Для таких случаев используется Коэффициент вариации (Coefficient of Variation, CV) - отношение Стандартного отклонения к среднему арифметическому , выраженного в процентах.
В MS EXCEL 2007 и более ранних версиях для вычисления Стандартного отклонения выборки используется функция =СТАНДОТКЛОН() , англ. название STDEV, т.е. STandard DEViation. С версии MS EXCEL 2010 рекомендуется использовать ее аналог =СТАНДОТКЛОН.В() , англ. название STDEV.S, т.е. Sample STandard DEViation.
Кроме того, начиная с версии MS EXCEL 2010 присутствует функция СТАНДОТКЛОН.Г() , англ. название STDEV.P, т.е. Population STandard DEViation, которая вычисляет стандартное отклонение для генеральной совокупности . Все отличие сводится к знаменателю: вместо n-1 как у СТАНДОТКЛОН.В() , у СТАНДОТКЛОН.Г() в знаменателе просто n.
Стандартное отклонение
можно также вычислить непосредственно по нижеуказанным формулам (см. файл примера
)
=КОРЕНЬ(КВАДРОТКЛ(Выборка)/(СЧЁТ(Выборка)-1))
=КОРЕНЬ((СУММКВ(Выборка)-СЧЁТ(Выборка)*СРЗНАЧ(Выборка)^2)/(СЧЁТ(Выборка)-1))
Другие меры разброса
Функция КВАДРОТКЛ() вычисляет сумму квадратов отклонений значений от их среднего . Эта функция вернет тот же результат, что и формула =ДИСП.Г(Выборка )*СЧЁТ(Выборка ) , где Выборка - ссылка на диапазон, содержащий массив значений выборки (). Вычисления в функции КВАДРОТКЛ() производятся по формуле:

Функция СРОТКЛ() является также мерой разброса множества данных. Функция СРОТКЛ() вычисляет среднее абсолютных значений отклонений значений от среднего . Эта функция вернет тот же результат, что и формула =СУММПРОИЗВ(ABS(Выборка-СРЗНАЧ(Выборка)))/СЧЁТ(Выборка) , где Выборка - ссылка на диапазон, содержащий массив значений выборки.
Вычисления в функции СРОТКЛ () производятся по формуле:






