1. Сопоставляемые показатели должны быть измерены в номинальной шкале (например, пол пациента - мужской или женский) или в порядковой (например, степень артериальной гипертензии, принимающая значения от 0 до 3).
2. Данный метод позволяет проводить анализ не только четырехпольных таблиц, когда и фактор, и исход являются бинарными переменными, то есть имеют только два возможных значения (например, мужской или женский пол, наличие или отсутствие определенного заболевания в анамнезе...). Критерий хи-квадрат Пирсона может применяться и в случае анализа многопольных таблиц, когда фактор и (или) исход принимают три и более значений.
3. Сопоставляемые группы должны быть независимыми, то есть критерий хи-квадрат не должен применяться при сравнении наблюдений "до-"после". В этих случаях проводится тест Мак-Немара (при сравнении двух связанных совокупностей) или рассчитывается Q-критерий Кохрена (в случае сравнения трех и более групп).
4. При анализе четырехпольных таблиц ожидаемые значения в каждой из ячеек должны быть не менее 10. В том случае, если хотя бы в одной ячейке ожидаемое явление принимает значение от 5 до 9, критерий хи-квадрат должен рассчитываться с поправкой Йейтса . Если хотя бы в одной ячейке ожидаемое явление меньше 5, то для анализа должен использоваться точный критерий Фишера .
5. В случае анализа многопольных таблиц ожидаемое число наблюдений не должно принимать значения менее 5 более чем в 20% ячеек.
Для расчета критерия хи-квадрат необходимо:
1. Рассчитываем ожидаемое количество наблюдений для каждой из ячеек таблицы сопряженности (при условии справедливости нулевой гипотезы об отсутствии взаимосвязи) путем перемножения сумм рядов и столбцов с последующим делением полученного произведения на общее число наблюдений. Общий вид таблицы ожидаемых значений представлен ниже:
| Исход есть (1) | Исхода нет (0) | Всего | |
| Фактор риска есть (1) | (A+B)*(A+C) / (A+B+C+D) | (A+B)*(B+D)/ (A+B+C+D) | A + B |
| Фактор риска отсутствует (0) | (C+D)*(A+C)/ (A+B+C+D) | (C+D)*(B+D)/ (A+B+C+D) | C + D |
| Всего | A + C | B + D | A+B+C+D |
2. Находим значение критерия χ 2 по следующей формуле:
где i – номер строки (от 1 до r), j – номер столбца (от 1 до с), O ij – фактическое количество наблюдений в ячейке ij, E ij – ожидаемое число наблюдений в ячейке ij.
В том случае, если число ожидаемого явления меньше 10 хотя бы в одной ячейке, при анализе четырехпольных таблиц должен рассчитываться критерий хи-квадрат с поправкой Йейтса . Данная поправка позволяет уменьшить вероятность ошибки первого типа, т.е обнаружения различий там, где их нет. Поправка Йейтса заключается в вычитании 0,5 из абсолютного значения разности между фактическим и ожидаемым количеством наблюдений в каждой ячейке, что ведет к уменьшению величины критерия хи-квадрат.
Формула для расчета критерия χ 2 с поправкой Йейтса следующая:

3. Определяем число степеней свободы по формуле: f = (r – 1) × (c – 1) . Ссответственно, для четырехпольной таблицы, в которой 2 ряда (r = 2) и 2 столбца (c = 2), число степеней свободы составляет f 2x2 = (2 - 1)*(2 - 1) = 1.
4. Сравниваем значение критерия χ 2 с критическим значением при числе степеней свободы f (по таблице).
Данный алгоритм применим как для четырехпольных, так и для многопольных таблиц.
Как интерпретировать значение критерия хи-квадрат Пирсона?
В том случае, если полученное значение критерия χ 2 больше критического, делаем вывод о наличии статистической взаимосвязи между изучаемым фактором риска и исходом при соответствующем уровне значимости.
Пример расчета критерия хи-квадрат Пирсона
Определим статистическую значимость влияния фактора курения на частоту случаев артериальной гипертонии по рассмотренной выше таблице:
1. Рассчитываем ожидаемые значения для каждой ячейки:
2. Находим значение критерия хи-квадрат Пирсона:
χ 2 = (40-33.6) 2 /33.6 + (30-36.4) 2 /36.4 + (32-38.4) 2 /38.4 + (48-41.6) 2 /41.6 = 4.396.
3. Число степеней свободы f = (2-1)*(2-1) = 1. Находим по таблице критическое значение критерия хи-квадрат Пирсона, которое при уровне значимости p=0.05 и числе степеней свободы 1 составляет 3.841.
4. Сравниваем полученное значение критерия хи-квадрат с критическим: 4.396 > 3.841, следовательно зависимость частоты случаев артериальной гипертонии от наличия курения - статистически значима. Уровень значимости данной взаимосвязи соответствует p<0.05.
| Число степеней свободы, f | χ 2 при p=0.05 | χ 2 при p=0.01 |
| 3.841 | 6.635 | |
| 5.991 | 9.21 | |
| 7.815 | 11.345 | |
| 9.488 | 13.277 | |
| 11.07 | 15.086 | |
| 12.592 | 16.812 | |
| 14.067 | 18.475 | |
| 15.507 | 20.09 | |
| 16.919 | 21.666 | |
| 18.307 | 23.209 | |
| 19.675 | 24.725 | |
| 21.026 | 26.217 | |
| 22.362 | 27.688 | |
| 23.685 | 29.141 | |
| 24.996 | 30.578 | |
| 26.296 | ||
| 27.587 | 33.409 | |
| 28.869 | 34.805 | |
| 30.144 | 36.191 | |
| 31.41 | 37.566 |
При проведении теста хи-квадрат проверяется взаимная независимость двух переменных таблицы сопряженности и благодаря этому косвенно выясняется зависимость обоих переменных. Две переменные считаются взаимно независимыми, если наблюдаемые частоты (f 0) в ячейках совпадают с ожидаемыми частотами (f e).
Для того, чтобы провести тест хи-квадрат с помощью SPSS, выполните следующие действия:
- Выберите в меню команды Analyze (Анализ) › Descriptive Statistics (Дескриптивные статистики) › Crosstabs… (Таблицы сопряженности)
- Кнопкой Reset (Сброс) удалите возможные настройки.
- Перенесите переменную sex в список строк, а переменную psyche - в список столбцов.
- Щелкните на кнопке Cells… (Ячейки). В диалоговом окне установите, кроме предлагаемого по умолчанию флажка Observed , еще флажки Expected и Standardized . Подтвердите выбор кнопкой Continue .
- Щелкните на кнопке Statistics… (Статистика).
Откроется описанное выше диалоговое окно Crosstabs: Statistics .
- Установите флажок Chi-square (Хи-квадрат). Щелкните на кнопке Continue , а в главном диалоговом окне - на ОК .
Вы получите следующую таблицу сопряженности.
Пол * Психическое состояние. Таблица сопряженности .
| Психическое состояние | Total | ||||||
| Крайне неустойчивое | Неустойчивое | Устойчивое | Очень устойчивое | ||||
| Пол | женский | Count | 16 | 18 | 9 | 1 | 44 |
| Expected Count | 7.9 | 16.6 | 17.0 | 2.5 | 44.0 | ||
| Std. Residual | 2.9 | 0.3 | -1.9 | -0.9 | |||
| Мужской | Count | 3 | 22 | 32 | 5 | 62 | |
| Expected Count | 11.1 | 23.4 | 24.0 | 3.5 | 62.0 | ||
| Std. Residual | -2.4 | -0.3 | 1.6 | 0.8 | |||
| Total | Count | 19 | 40 | 41 | 6 | 106 | |
| Expected Count | 19.0 | 40.0 | 41.0 | 6.0 | 106.0 | ||
Кроме того, в окне просмотра будут показаны результаты теста хи-квадрат:
Chi-Square Tests (Тесты хи-квадрат)
- а. 2 cells (25.0%) have expected count less than 5. The minimum expected count is 2.49 (2 ячейки (25%) имеют ожидаемую частоту менее 5. Минимальная ожидаемая частота 2.49.)
Для вычисления критерия хи-квадрат применяются три различных подхода: формула Пирсона, поправка на правдоподобие и тест Мантеля-Хэнзеля. Если таблица сопряженности имеет четыре поля и ожидаемая вероятность менее 5, дополнительно выполняется точный тест Фишера.
Критерий хи-квадрат по Пирсону
Обычно для вычисления критерия хи-квадрат используется формула Пирсона:
Здесь вычисляется сумма квадратов стандартизованных остатков по всем полям таблицы сопряженности. Поэтому поля с более высоким стандартизованным остатком вносят более весомый вклад в численное значение критерия хи-квадрат и, следовательно, - в значимый результат. Согласно правилу, приведенному в разделе 8.7.2, стандартизованный остаток 2 или более указывает на значимое расхождение между наблюдаемой и ожидаемой частотами.
В рассматриваемом нами примере формула Пирсона дает максимально значимую величину критерия хи-квадрат (р<0.001). Если рассмотреть стандартизованные остатки в отдельных полях таблицы сопряженности, то на основе вышеприведенного правила можно сделать вывод, что эта значимость в основном определяется полями, в которых переменная psyche имеет значение "крайне неустойчивое". У женщин это значение сильно повышено, а у мужчин - понижено.
Корректность проведения теста хи-квадрат определяется двумя условиями: во-первых, ожидаемые частоты < 5 должны встречаться не более чем в 20% полей таблицы; во-вторых, суммы по строкам и столбцам всегда должны быть больше нуля.
Однако в рассматриваемом примере это условие выполняется не полностью. Как указывает примечание после таблицы теста хи-квадрат, 25% полей имеют ожидаемую частоту менее 5. Однако, так как допустимый предел4в 20% превышен лишь ненамного и эти поля, вследствие своего очень малого стандартизованного остатка, вносят весьма незначительную долю в величину критерия хи-квадрат, это нарушение можно считать несущественным.
Критерий хи-квадрат с поправкой на правдоподобие
Альтернативой формуле Пирсона для вычисления критерия хи-квадрат является поправка на правдоподобие:

При большом объеме выборки формула Пирсона и подправленная формула дают очень близкие результаты. В нашем примере критерий хи-квадрат с поправкой на правдоподобие составляет 23.688.
Тест Мантеля-Хэнзеля
Дополнительно в таблице сопряженности под обозначением linear-by-linear ("линейный-по-линейному") выводится значение теста Мантеля-Хэнзеля (20.391). Эта форма критерия хи-квадрат с поправкой Мантеля-Хэнзеля - еще одна мера линейной зависимости между строками и столбцами таблицы сопряженности. Она определяется как произведение коэффициента корреляции Пирсона на количество наблюдений, уменьшенное на единицу:
![]()
Полученный таким образом критерий имеет одну степень свободы. Метод Мантеля-Хэнзеля используется всегда, когда в диалоговом окне Crosstabs: Statistics установлен флажок Chi-square . Однако для данных, относящихся к с номинальной шкале, этот критерий неприменим.
Министерство образования и науки Российской Федерации
Федеральное агентство по образованию города Иркутска
Байкальский государственный университет экономики и права
Кафедра Информатики и Кибернетики
Распределение "хи-квадрат" и его применение
Колмыкова Анна Андреевна
студентка 2 курса
группы ИС-09-1
Для обработки полученных данных используем критерий хи-квадрат.
Для этого построим таблицу распределения эмпирических частот, т.е. тех частот, которые мы наблюдаем:
Теоретически, мы ожидаем, что частоты распределятся равновероятно, т.е. частота распределится пропорционально между мальчиками и девочками. Построим таблицу теоретических частот. Для этого умножим сумму по строке на сумму по столбцу и разделим получившееся число на общую сумму (s).
Итоговая таблица для вычислений будет выглядеть так:
χ2 = ∑(Э - Т)² / Т
n = (R - 1), где R – количество строк в таблице.
В нашем случае хи-квадрат = 4,21; n = 2.
По таблице критических значений критерия находим: при n = 2 и уровне ошибки 0,05 критическое значение χ2 = 5,99.
Полученное значение меньше критического, а значит принимается нулевая гипотеза.
Вывод: учителя не придают значение полу ребенка при написании ему характеристики.
Приложение
Критические точки распределения χ2
Таблица 1

Заключение
Студенты почти всех специальностей изучают в конце курса высшей математики раздел "теория вероятностей и математическая статистика", реально они знакомятся лишь с некоторыми основными понятиями и результатами, которых явно не достаточно для практической работы. С некоторыми математическими методами исследования студенты встречаются в специальных курсах (например, таких, как "Прогнозирование и технико-экономическое планирование", "Технико-экономический анализ", "Контроль качества продукции", "Маркетинг", "Контроллинг", "Математические методы прогнозирования", "Статистика" и др. – в случае студентов экономических специальностей), однако изложение в большинстве случаев носит весьма сокращенный и рецептурный характер. В результате знаний у специалистов по прикладной статистике недостаточно.
Поэтому большое значение имеет курс "Прикладная статистика" в технических вузах, а в экономических вузах – курса "Эконометрика", поскольку эконометрика – это, как известно, статистический анализ конкретных экономических данных.
Теория вероятности и математическая статистика дают фундаментальные знания для прикладной статистики и эконометрики.
Они необходимы специалистам для практической работы.
Я рассмотрела непрерывную вероятностную модель и постаралась на примерах показать ее используемость.
Список используемой литературы
1. Орлов А.И. Прикладная статистика. М.: Издательство "Экзамен", 2004.
2. Гмурман В.Е. Теория вероятностей и математическая статистика. М.: Высшая школа, 1999. – 479с.
3. Айвозян С.А. Теория вероятностей и прикладная статистика, т.1. М.: Юнити, 2001. – 656с.
4. Хамитов Г.П., Ведерникова Т.И. Вероятности и статистика. Иркутск: БГУЭП, 2006 – 272с.
5. Ежова Л.Н. Эконометрика. Иркутск: БГУЭП, 2002. – 314с.
6. Мостеллер Ф. Пятьдесят занимательных вероятностных задач с решениями. М. : Наука, 1975. – 111с.
7. Мостеллер Ф. Вероятность. М. : Мир, 1969. – 428с.
8. Яглом А.М. Вероятность и информация. М. : Наука, 1973. – 511с.
9. Чистяков В.П. Курс теории вероятностей. М.: Наука, 1982. – 256с.
10. Кремер Н.Ш. Теория вероятностей и математическая статистика. М.: ЮНИТИ, 2000. – 543с.
11. Математическая энциклопедия, т.1. М.: Советская энциклопедия, 1976. – 655с.
12. http://psystat.at.ua/ - Статистика в психологии и педагогике. Статья Критерий Хи-квадрат.
Рассмотрим Распределение ХИ-квадрат. С помощью функции MS EXCEL ХИ2.РАСП() построим графики функции распределения и плотности вероятности, поясним применение этого распределения для целей математической статистики.
Распределение ХИ-квадрат (Х 2 , ХИ2, англ. Chi - squared distribution ) применяется в различных методах математической статистики:
- при построении ;
- при ;
- при (согласуются ли эмпирические данные с нашим предположением о теоретической функции распределения или нет, англ. Goodness-of-fit)
- при (используется для определения связи между двумя категориальными переменными, англ. Chi-square test of association).
Определение : Если x 1 , x 2 , …, x n независимые случайные величины, распределенные по N(0;1), то распределение случайной величины Y=x 1 2 + x 2 2 +…+ x n 2 имеет распределение Х 2 с n степенями свободы.
Распределение Х 2 зависит от одного параметра, который называется степенью свободы (df , degrees of freedom ). Например, при построении число степеней свободы равно df=n-1, где n – размер выборки .
Плотность распределения
Х 2
выражается формулой:
Графики функций
Распределение Х 2 имеет несимметричную форму, равно n, равна 2n.
В файле примера на листе График приведены графики плотности распределения вероятности и интегральной функции распределения .

Полезное свойство ХИ2-распределения
Пусть x 1 , x 2 , …, x n независимые случайные величины, распределенные по нормальному закону
с одинаковыми параметрами μ и σ, а X cр
является арифметическим средним
этих величин x.
Тогда случайная величина y
равная

Имеет Х 2 -распределение с n-1 степенью свободы. Используя определение вышеуказанное выражение можно переписать следующим образом:

Следовательно, выборочное распределение статистики y, при выборке из нормального распределения , имеет Х 2 -распределение с n-1 степенью свободы.
Это свойство нам потребуется при . Т.к. дисперсия может быть только положительным числом, а Х 2 -распределение используется для его оценки, то y д.б. >0, как и указано в определении.
ХИ2-распределение в MS EXCEL
В MS EXCEL, начиная с версии 2010, для Х 2 -распределения имеется специальная функция ХИ2.РАСП() , английское название – CHISQ.DIST(), которая позволяет вычислить плотность вероятности (см. формулу выше) и (вероятность, что случайная величина Х, имеющая ХИ2 -распределение , примет значение меньше или равное х, P{X <= x}).
Примечание : Т.к. ХИ2-распределение является частным случаем , то формула =ГАММА.РАСП(x;n/2;2;ИСТИНА) для целого положительного n возвращает тот же результат, что и формула =ХИ2.РАСП(x;n; ИСТИНА) или =1-ХИ2.РАСП.ПХ(x;n) . А формула =ГАММА.РАСП(x;n/2;2;ЛОЖЬ) возвращает тот же результат, что и формула =ХИ2.РАСП(x;n; ЛОЖЬ) , т.е. плотность вероятности ХИ2-распределения.
Функция ХИ2.РАСП.ПХ()
возвращает функцию распределения
, точнее - правостороннюю вероятность, т.е. P{X > x}. Очевидно, что справедливо равенство
=ХИ2.РАСП.ПХ(x;n)+ ХИ2.РАСП(x;n;ИСТИНА)=1
т.к. первое слагаемое вычисляет вероятность P{X > x}, а второе P{X <= x}.
До MS EXCEL 2010 в EXCEL была только функция ХИ2РАСП() , которая позволяет вычислить правостороннюю вероятность, т.е. P{X > x}. Возможности новых функций MS EXCEL 2010 ХИ2.РАСП() и ХИ2.РАСП.ПХ() перекрывают возможности этой функции. Функция ХИ2РАСП() оставлена в MS EXCEL 2010 для совместимости.
ХИ2.РАСП() является единственной функцией, которая возвращает плотность вероятности ХИ2-распределения (третий аргумент должен быть равным ЛОЖЬ). Остальные функции возвращают интегральную функцию распределения , т.е. вероятность того, что случайная величина примет значение из указанного диапазона: P{X <= x}.
Вышеуказанные функции MS EXCEL приведены в .
Примеры
Найдем вероятность, что случайная величина Х примет значение меньше или равное заданного x : P{X <= x}. Это можно сделать несколькими функциями:
ХИ2.РАСП(x; n; ИСТИНА)
=1-ХИ2.РАСП.ПХ(x; n)
=1-ХИ2РАСП(x; n)
Функция ХИ2.РАСП.ПХ() возвращает вероятность P{X > x}, так называемую правостороннюю вероятность, поэтому, чтобы найти P{X <= x}, необходимо вычесть ее результат от 1.
Найдем вероятность, что случайная величина Х примет значение больше заданного x : P{X > x}. Это можно сделать несколькими функциями:
1-ХИ2.РАСП(x; n; ИСТИНА)
=ХИ2.РАСП.ПХ(x; n)
=ХИ2РАСП(x; n)
Обратная функция ХИ2-распределения
Обратная функция используется для вычисления альфа - , т.е. для вычисления значений x при заданной вероятности альфа , причем х должен удовлетворять выражению P{X <= x}=альфа .
Функция ХИ2.ОБР() используется для вычисления доверительных интервалов дисперсии нормального распределения .
Функция ХИ2.ОБР.ПХ() используется для вычисления , т.е. если в качестве аргумента функции указан уровень значимости, например 0,05, то функция вернет такое значение случайной величины х, для которого P{X>x}=0,05. В качестве сравнения: функция ХИ2.ОБР() вернет такое значение случайной величины х, для которого P{X<=x}=0,05.
В MS EXCEL 2007 и ранее вместо ХИ2.ОБР.ПХ() использовалась функция ХИ2ОБР() .
Вышеуказанные функции можно взаимозаменять, т.к. следующие формулы возвращают один и тот же результат:
=ХИ.ОБР(альфа;n)
=ХИ2.ОБР.ПХ(1-альфа;n)
=ХИ2ОБР(1- альфа;n)
Некоторые примеры расчетов приведены в файле примера на листе Функции .
Функции MS EXCEL, использующие ХИ2-распределение
Ниже приведено соответствие русских и английских названий функций:
ХИ2.РАСП.ПХ()
- англ. название CHISQ.DIST.RT, т.е. CHI-SQuared DISTribution Right Tail, the right-tailed Chi-square(d) distribution
ХИ2.ОБР()
- англ. название CHISQ.INV, т.е. CHI-SQuared distribution INVerse
ХИ2.ПХ.ОБР()
- англ. название CHISQ.INV.RT, т.е. CHI-SQuared distribution INVerse Right Tail
ХИ2РАСП()
- англ. название CHIDIST, функция эквивалентна CHISQ.DIST.RT
ХИ2ОБР()
- англ. название CHIINV, т.е. CHI-SQuared distribution INVerse
Оценка параметров распределения
Т.к. обычно ХИ2-распределение используется для целей математической статистики (вычисление доверительных интервалов, проверки гипотез и др.), и практически никогда для построения моделей реальных величин, то для этого распределения обсуждение оценки параметров распределения здесь не производится.
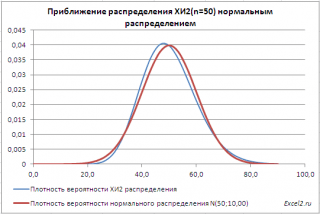
Приближение ХИ2-распределения нормальным распределением
При числе степеней свободы n>30 распределение Х 2
хорошо аппроксимируется нормальным распределением
со средним значением
μ=n и дисперсией σ
=2*n (см. файл примера лист Приближение
).
Использование этого критерия основано на применении такой меры (статистики) расхождения между теоретическим F (x ) и эмпирическим распределением F * п (x ) , которая приближенно подчиняется закону распределения χ 2 . Гипотеза Н 0 о согласованности распределений проверяется путем анализа распределения этой статистики. Применение критерия требует построения статистического ряда.
Итак, пусть выборка представлена статистическим рядом с количеством разрядов M . Наблюдаемая частота попаданий в i - й разряд n i . В соответствии с теоретическим законом распределения ожидаемая частота попаданий в i -й разряд составляет F i . Разность между наблюдаемой и ожидаемой частотой составит величину (n i – F i ). Для нахождения общей степени расхождения между F (x ) и F * п (x ) необходимо подсчитать взвешенную сумму квадратов разностей по всем разрядам статистического ряда
Величина χ 2 при неограниченном увеличении n имеет χ 2 -распределение (асимптотически распределена как χ 2). Это распределение зависит от числа степеней свободы k , т.е. количества независимых значений слагаемых в выражении (3.7). Число степеней свободы равно числу y минус число линейных связей, наложенных на выборку. Одна связь существует в силу того, что любая частота может быть вычислена по совокупности частот в оставшихся M –1 разрядах. Кроме того, если параметры распределения неизвестны заранее, то имеется еще одно ограничение, обусловленное подгонкой распределения к выборке. Если по выборке определяются S параметров распределения, то число степеней свободы составит k = M – S –1.
Область принятия гипотезы Н 0 определяется условием χ 2 < χ 2 (k ; a ) , где χ 2 (k ; a ) – критическая точка χ2-распределения с уровнем значимости a . Вероятность ошибки первого рода равна a , вероятность ошибки второго рода четко определить нельзя, потому что существует бесконечно большое множество различных способов несовпадения распределений. Мощность критерия зависит от количества разрядов и объема выборки. Критерий рекомендуется применять при n >200, допускается применение при n >40, именно при таких условиях критерий состоятелен (как правило, отвергает неверную нулевую гипотезу).
Алгоритм проверки по критерию
1. Построить гистограмму равновероятностным способом.
2. По виду гистограммы выдвинуть гипотезу
H 0: f (x ) = f 0 (x ),
H 1: f (x ) ¹ f 0 (x ),
где f 0 (x ) - плотность вероятности гипотетического закона распределения (например, равномерного, экспоненциального, нормального).
Замечание . Гипотезу об экспоненциальном законе распределения можно выдвигать в том случае, если все числа в выборке положительные.
3. Вычислить значение критерия по формуле
 ,
,
где  частота
попадания вi
-тый интервал;
частота
попадания вi
-тый интервал;
p i - теоретическая вероятность попадания случайной величины вi - тый интервал при условии, что гипотезаH 0 верна.
Формулы для расчета p i в случае экспоненциального, равномерного и нормального законов соответственно равны.
Экспоненциальный закон
 . (3.8)
. (3.8)
При этом A 1 = 0, B m = +¥.
Равномерный закон
Нормальный закон
 . (3.10)
. (3.10)
При этом A 1 = -¥, B M = +¥.
Замечания . После вычисления всех вероятностей p i проверить, выполняется ли контрольное соотношение

Функция Ф(х )- нечетная. Ф(+¥) = 1.
4.
Из таблицы " Хи-квадрат" Приложения
выбирается значение
 ,
гдеa
- заданный уровень значимости (a
= 0,05 или a
= 0,01), а k
-
число степеней свободы, определяемое
по формуле
,
гдеa
- заданный уровень значимости (a
= 0,05 или a
= 0,01), а k
-
число степеней свободы, определяемое
по формуле
k = M - 1 - S .
Здесь S - число параметров, от которых зависит выбранный гипотезой H 0 закон распределения. Значения S для равномерного закона равно 2, для экспоненциального - 1, для нормального - 2.
5.
Если
 ,
то гипотезаH
0
отклоняется. В противном случае нет
оснований ее отклонить: с вероятностью
1 - b
она верна, а с вероятностью - b
неверна, но величина b
неизвестна.
,
то гипотезаH
0
отклоняется. В противном случае нет
оснований ее отклонить: с вероятностью
1 - b
она верна, а с вероятностью - b
неверна, но величина b
неизвестна.
Пример3 . 1. С помощью критерия c 2 выдвинуть и проверить гипотезу о законе распределения случайной величины X , вариационный ряд, интервальные таблицы и гистограммы распределения которой приведены в примере 1.2. Уровень значимости a равен 0,05.
Решение . По виду гистограмм выдвигаем гипотезу о том, что случайная величина X распределена по нормальному закону:
H 0: f (x ) = N (m , s);
H 1: f (x ) ¹ N (m , s).
Значение критерия вычисляем по формуле:
 (3.11)
(3.11)
Как отмечалось выше, при проверке гипотезы предпочтительнее использовать равновероятностную гистограмму. В этом случае

Теоретические вероятности p i рассчитываем по формуле (3.10). При этом полагаем, что

p 1 = 0,5(Ф((-4,5245+1,7)/1,98)-Ф((-¥+1,7)/1,98)) = 0,5(Ф(-1,427)-Ф(-¥)) =
0,5(-0,845+1) = 0,078.
p 2 = 0,5(Ф((-3,8865+1,7)/1,98)-Ф((-4,5245+1,7)/1,98)) =
0,5(Ф(-1,104)+0,845) = 0,5(-0,729+0,845) = 0,058.
p 3 = 0,094; p 4 = 0,135; p 5 = 0,118; p 6 = 0,097; p 7 = 0,073; p 8 = 0,059; p 9 = 0,174;
p 10 = 0,5(Ф((+¥+1,7)/1,98)-Ф((0,6932+1,7)/1,98)) = 0,114.
После этого проверяем выполнение контрольного соотношения

100 × (0,0062 + 0,0304 + 0,0004 + 0,0091 + 0,0028 + 0,0001 + 0,0100 +
0,0285 + 0,0315 + 0,0017) = 100 × 0,1207 = 12,07.
После этого из таблицы "Хи - квадрат" выбираем критическое значение
 .
.
Так
как
 то гипотезаH
0
принимается (нет основания ее отклонить).
то гипотезаH
0
принимается (нет основания ее отклонить).





